

With the rise of LLMs, there has been a corresponding increase in the use of synthetic data. Triangulation studies have found that the outputs are generally within around 10% of real-world data, with some researchers even suggesting that synthetic data is better in certain areas such as privacy preservation and augmenting small sample sizes. We wanted to understand what this means for the future of marketing and whether it’s time to do away with expensive surveys and primary research, so we carried out some tests of our own to see just how well AI models can replace this data.
Benchmarking
The GWI Core survey is widely used as an industry standard for market research and we therefore used this as a ‘source of truth’ for comparison.
As there are several thousand data points within this survey, we limited our analysis to the four questions which are almost universally used as a starting point for understanding audiences: Brand Discovery, Brand Advocacy, Online Product Research, and Online Purchase Drivers.
We also limited ourselves to responses from UK adults aged 16-65 across the last 4 quarters so that we could remove any country-specific nuances or biases from the data. We then collected the audience percentage responses for each attribute as a benchmark against which the LLMs could be measured.
Methodology
We introduced each LLM to our study by giving a brief overview of our aims and how we were going to approach the research.

We then carried out a statistical analysis of the synthetic data against the GWI survey data benchmark. This included the T-test, F-test, and Chi-Squared test to either accept or reject the null hypothesis, that is to say whether the synthetic data significantly differed from the benchmark data.
Statistical Analysis
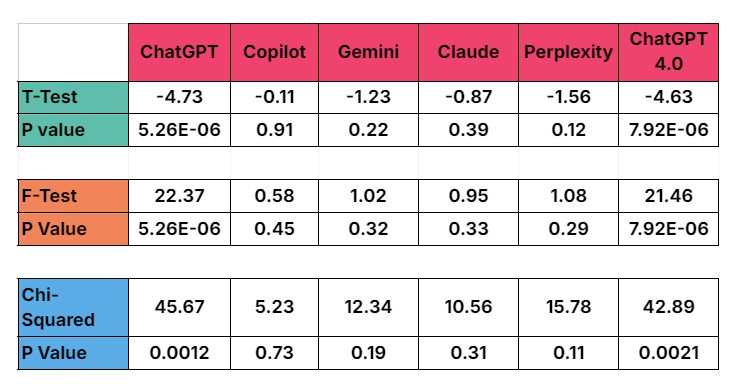
The null hypothesis states that there is no statistical difference between the LLM generated synthetic data and the real-world survey responses from GWI. A p-value of less than 0.05 means that we reject the null hypothesis, and therefore there is a statistically significant difference between the two outputs. A p-value of more than 0.05, on the other hand, suggests that there is no significant difference between the two results and the LLM data is essentially the same as the GWI responses.
Based on the results of the three statistical tests, Copilot, Gemini, Claude and Perplexity all show no statistically significant difference between the GWI survey data and the synthetic data in terms of means, variances and distributions. This suggests that the synthetic data can therefore be relied on with a relatively high degree of confidence.
Both ChatGPT and ChatGPT 4.0, on the other hand, produce p-values less than 0.05 and therefore there is a statistically significant difference between these outputs and the GWI survey data. Although the individual data points display a strong correlation, this synthetic data cannot therefore be relied upon.
Why is this important?
Although the possibilities offered by AI are exciting, it’s important to not get carried away. Whilst LLMs offer speed and cost efficiencies when compared to conducting real-world research, there are some key limitations in the outputs. Our study demonstrates that LLMs like Copilot can generate synthetic data that closely match real-world survey data, but it remains vital to evaluate the quality of this data if it is to guide decision-making.
Synthetic data is therefore a great starting point for research, enabling initial exploration, concept validation and trend analysis, but surveys like GWI can rest easy, safe in the knowledge that AI cannot fully replace the depth and accuracy of primary research… yet!
statistical analysis by Abi Wilson